第 11 章 最终配置与最终结果
这一章把前 10 章里逐步展开的所有改动收束到一组可以复述的、有数字支持的最终结果。
11.1 最终硬件与网络形态
Host
| 项目 | 规格 |
|---|---|
| CPU | Intel i9-13900K(24 核 8P+16E) |
| 内存 | 128 GB DDR5,4 条 32 GB DIMM,5400 MT/s |
| GPU | NVIDIA RTX 5090,32 GB GDDR7,带宽约 1792 GB/s |
| 网卡 | 4 × Intel E810-C SFP28(25 GbE),驱动 net_ice;1 × Realtek RTL8125(2.5 GbE,管理) |
| DPDK lcore 分配 | Port 0 → lcore 4, Port 1 → lcore 6, Port 2 → lcore 8, Port 3 → lcore 2 |
Duck 节点群
| 项目 | 规格 |
|---|---|
| 数量 | 32 台 Intel N100(准系统 2024-12 采购) |
| CPU | N100,4 核 4 线程,AVX2 + FMA,全核持续约 2.9 GHz |
| 内存 | 32 GB DDR4-3200 单通道 |
| 网络 | 2.5 GbE(RTL8125)上联 |
网络拓扑
- 4 个隔离广播域:
10.21.[1-4].0/24 - 交换机:ZX-SWTG3DE48A6S(48×2.5G + 4×25G uplink)
- 每个子网:host 的 1 个 25 GbE 口 + 8 只鸭子各 1 个 2.5 GbE 口
- Host 侧 4 个 DPDK worker 各自独立占用一个 NIC,互不干扰
图:25G 交换机管理界面,显示 4 个 25G uplink 口和多个 2.5G 接入端口的链路状态。
11.2 最终模型与环境配置
模型
- DeepSeek-V3.2
- checkpoint 总参数约 685B(含 MTP head),磁盘约 688 GB
fp9_gemv_multiple_of = 64(sub-128 解锁 tp=24+,见第 8 章)- shared experts 本地 GPU 端(Triton fp8),routed experts 走 duck
关键环境开关
DUCK_TRITON_FP8_LINEAR=1 # shared experts 走 Triton fp8
DUCK_V32_MTP1_PAIR_OVERLAP=1 # MTP1 dual-lane overlap运行配置
MODEL_NAME = "/home/pigeon/models/DeepSeek-V3.2"
MODEL_KWARGS = {
"use_duck": True,
"duck_tp_size": 32,
"device": "cuda",
"mock_duck": False,
"fp9_gemv_multiple_of": 64,
"flattened_decode": True,
"v32_attention_impl": "official_fp8",
"v32_static_graph_max_model_len": 2048,
"v32_mtp1_track_accuracy": True,
"v32_mtp1_print_each_step": True,
"v32_mtp1_online": True,
}默认开启的机制
以下机制在当前代码里都是 默认开启 的(无需额外环境变量):
- persistent judge:
DUCK_FP9_PERSISTENT_JUDGE=1默认开,decode forward 走judge-open-smp → judge-step,prepare 和 prefill 也复用同一 session(9bffc97) - flattened decode:CUDA Graph + 分阶段 runtime(第 7 章)
- final fp9 kernels:exact 64 signword_pf、exact 128 prescaled、general 64/128 fast dot(第 8 章)
以下机制需要显式环境变量:
- MTP1 dual-lane overlap:需要
DUCK_V32_MTP1_PAIR_OVERLAP=1。pair overlap 曾在 2026-03-27 因 correctness regression 被短暂切回默认关闭,之后在最终长跑中显式打开。
11.3 最终结果 overview
到 2026 年 4 月,系统已经跑过一组共 7 个 testcase 的完整档案,覆盖短 prompt 长输出、长 prompt 中等输出、极短问候等多种场景。这里先把当前最具代表性的两条 case 摆出来,随后给出详情。
11.3.1 两条代表性 testcase 概览
| case | input_len | output_len | ttft | prefill | tpot | decode | Token #1 离群值 |
|---|---|---|---|---|---|---|---|
02-prime-2k | 11 | 2037 | 0.861 s | 12.775 tok/s | 0.062 s | 16.171 tok/s | 763.9 ms |
05-long-input-1 | 1481 | 567 | 74.499 s | 19.880 tok/s | 0.070 s | 14.206 tok/s | 2020.8 ms |
两条 case 各有侧重:
02-prime-2k延续了原有的“质数查询 prompt”题材,把输出拉到 2037 tokens,decode 稳定在 16 tok/s 以上。05-long-input-1把项目自己的技术报告内容塞回 prompt,input_len≈1.5k,代表长 prefill + 大 TTFT 场景。
下面分别给出两条 case 的详细证据。
11.3.2 02-prime-2k 详情
prompt:104857601是质数吗
总指标:
Generation stats: time 126.724s, input_len 11, output_len 2037,
ttft 0.861s, tpot 0.062s,
prefill 12.775 tok/s, decode 16.171 tok/sper-token TPOT 图(steady tokens,token #2 起):
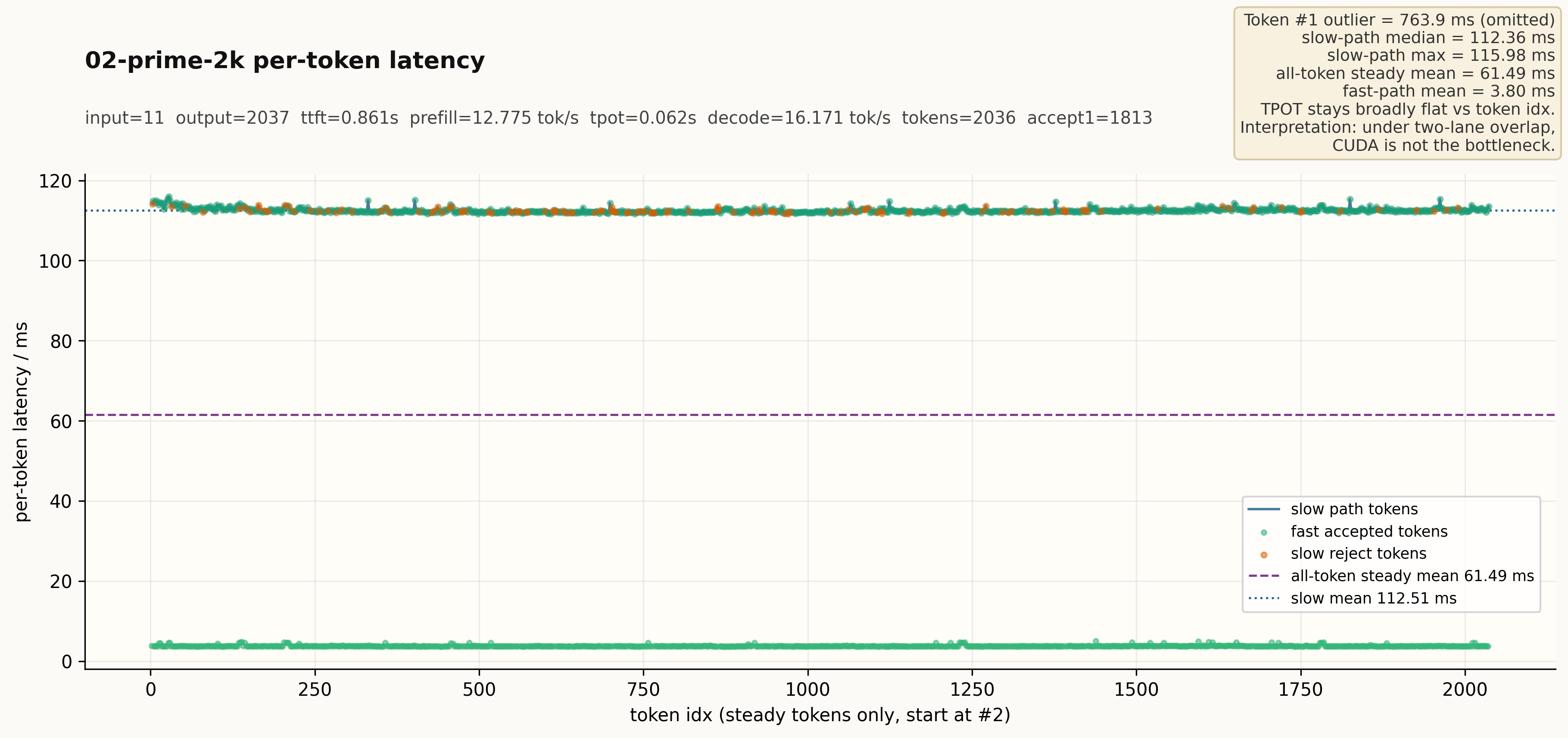
图:02-prime-2k 的逐 token 延迟分布(steady tokens 起,token #1 离群值已省略)。
slow path 中位约 112 ms,fast path 平均约 3.8 ms,CUDA 不是瓶颈。
Token #1 离群值约 763.9 ms,主要来自 warmup / fill 开销。Token #2 之后基本进入 two-lane overlap 的交替稳定形态,slow path 中位约 112 ms,fast path 平均约 3.8 ms——tpot 没有随着 seqlen 显著增加,说明在 two-lane overlap 下 CUDA 端持续快于 duck 侧 steady stage,没有把整体 tpot 顶高。
11.3.3 05-long-input-1 详情
prompt:你觉得这个项目真的能做到吗?为什么?(后续接了项目自身的技术报告内容作为上下文)
总指标:
Generation stats: time 114.782s, input_len 1481, output_len 567,
ttft 74.499s, tpot 0.070s,
prefill 19.880 tok/s, decode 14.206 tok/sper-token TPOT 图(steady tokens,token #2 起):
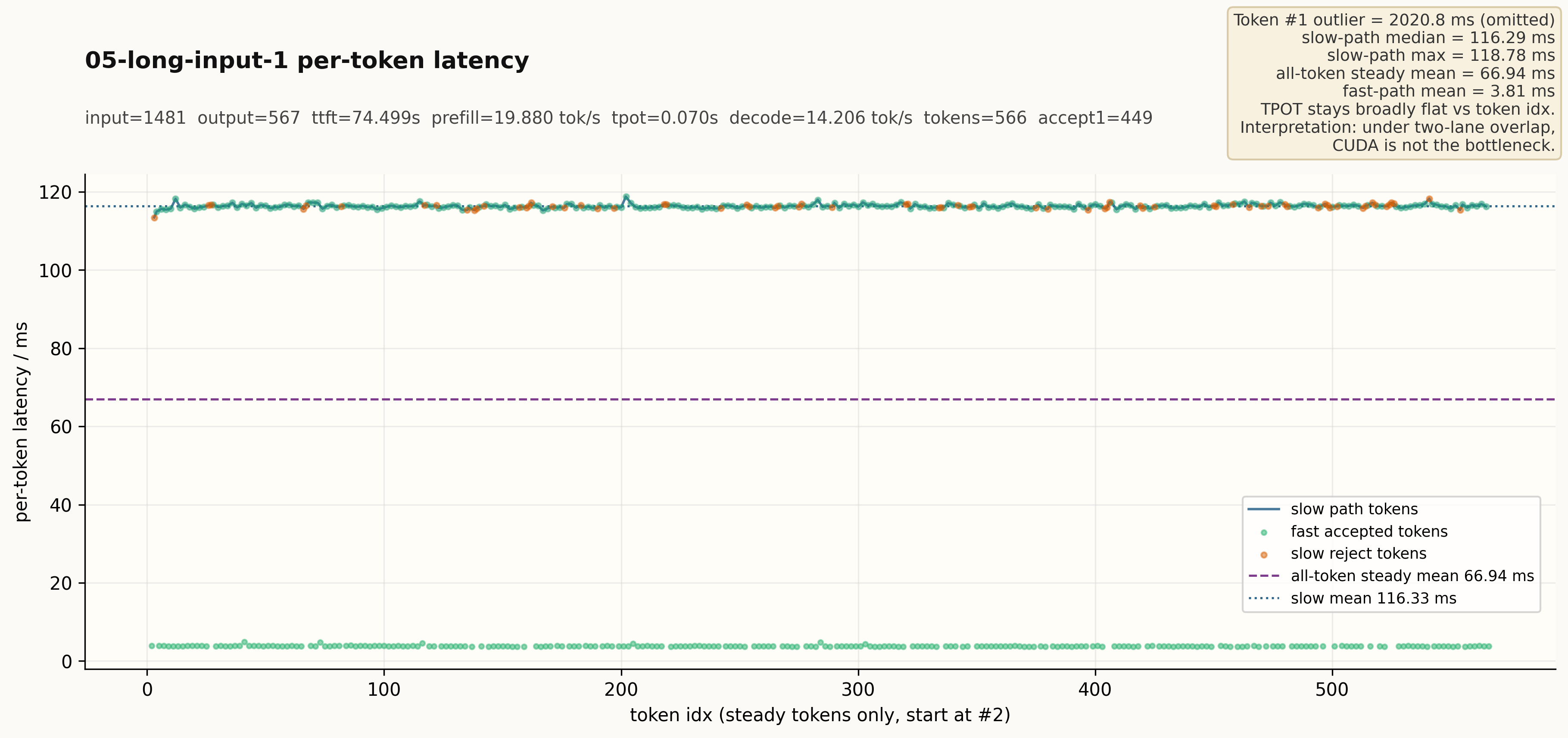
图:05-long-input-1 的逐 token 延迟分布(steady tokens 起)。
slow path 中位约 116 ms,fast path 平均约 3.8 ms。
Token #1 离群值约 2020.8 ms,明显高于短 prompt case,主要来自长 prefill 阶段的额外 warmup 开销。长输入下的 decode 仍然稳定在 14 tok/s 以上,没有因为 input_len≈1.5k 而明显降级。
11.4 结果分解:各项贡献各自是多少
下表是阶段性里程碑,不是严格可加的 ablation 表。其中
judge_gap、overlap ratio属于局部机制指标,tok/s属于当时完整系统形态下的端到端读数。每一行的数字反映的是“做到这一步时的系统状态”,而不是“这一项单独带来了多少提升”。
在 Qwen3 上的探索
很多关键机制——sub-128、SMP、persistent judge、flattened runtime——最初并不是在 V3.2 上验证的,而是在 Qwen3 dense(0.8B、17B)和 MoE(30B、235B)上逐步打通。
| 时间 | 模型 | 关键改动 | 指标 |
|---|---|---|---|
| 2026-03-12 | 30B tp=12 | sub-128 解锁(multiple_of=64) | ~13 tok/s |
| 2026-03-14 | 30B tp=24 | flattened runtime + CUDA Graph | 18 → 24 tok/s |
| 2026-03-16 | 235B tp=24 | 4 核 SMP MoE forward | 4.7 → ~9.0 tok/s |
| 2026-03-23 | 0.8B tp=8/tp=24 | persistent judge 真实 forward 验证并设为默认方案 | judge_gap: 138/133µs → 64/66µs |
这些模型上的实验证明了 persistent judge 的正确性、SMP 的 scaling 行为、以及 flattened runtime 的 graph 结构等核心机制的可行性。
DeepSeek-V3.2 的跑通与最终优化
| 日期 | 阶段 | 关键改动 | decode 吞吐 | 来源 |
|---|---|---|---|---|
| 2026-03-18 | 首轮真实跑通 | 临时 eager duck support,第一次正常中文对话 | ~3.15 tok/s | 第 6 章 |
| 2026-03-23 | clean official path 基线 | official_fp8 + flattened 路径收稳 | ~7.3 tok/s | 第 8 章 |
| 2026-03-23 | persistent judge 默认开启 | decode forward 切到 judge-open-smp → judge-step | 7.3 → 9.1 tok/s | 279d749 |
| 2026-03-24 | prepare/prefill 复用 session | session 建立前移,重新站上两位数 | ~10.0 tok/s | 9bffc97 |
| 2026-03-28 | MTP1 online 初步站住 | 双 lane online runtime 跑通 1024 tokens 长跑 | ~11.9 tok/s | d32c6fe |
| 2026-03-29 | predictive + device-owned 落地 | 三种边界接通,默认路径稳定 | ~13.9 ~ 14.2 tok/s | 8fee7b7 |
| 2026-03-30 | final fp9 kernels | final kernel patch 回 active 代码路径 | 15.3 tok/s | ab33e9e |
| 2026-04-08 | 多 testcase 验证 | 02-prime-2k 2037 tokens 长跑 | 16.171 tok/s | run_0408 |
overlap 长跑统计
从 2026-03-29 长跑 stderr 提取的 549 条 overlap 摘要统计均值:
| 指标 | 均值 |
|---|---|
| pair | 112.481 ms |
| serial(假设) | 198.892 ms |
| gain | 86.410 ms |
| ratio | 0.434 |
ratio ≈ 0.43 意味着 dual-lane overlap 稳定地把双 token 的总时间压到串行时间的大约 57%,每个 step 节约约 86 ms。这不是偶发现象,而是 549 个连续 step 的统计均值。
duck 侧带宽
这轮长跑中 MoE forward 的 duck 侧参数吞吐约 15.0 ~ 15.7 Gparam/s @ duck_max,折回字节约 16.9 ~ 17.7 GB/s @ duck_max,在正常工作区间内。
11.5 系统组件的通信关系
端到端数据流
┌──────────────┐
│ RTX 5090 │ ← attention + norm + residual
│ (CUDA Graph) │
└──────┬───────┘
│ D2H/H2D
┌──────┴───────┐
│ Rust FFI │ ← DPDK dispatch + GIL release
│ orchestration│ + MTP overlap gate
└──────┬───────┘
│ DPDK 25GbE
┌────────────┼────────────┐
│ │ │
┌─────────┴─────┐ ... │ ... ┌─────┴─────────┐
│ Duck 1~8 │ │ │ Duck 25~32 │
│ (Port 0) │ │ │ (Port 3) │
│ N100 4-core │ │ │ N100 4-core │
│fp9_kernels.elf│ │ │fp9_kernels.elf│
└───────────────┘ │ └───────────────┘
│
4 子网,各 8 duck
共 32 duck (tp=32)
图:4 组鸭子集群的物理布局(2026-02)。
每组 8 台 N100,共 32 台,对应 4 个 DPDK 子网。中间是 48 口 2.5G 交换机,接入了 4 个 25G 上联。
每层 decode 的执行序列
对于单层 decode:
- GPU 侧:CUDA Graph replay stage0(attention + layernorm + residual + rotary embedding)
- host 侧:
run_cpu_dispatch把 stage0 输出通过 DPDK 发给 duck - duck 侧:4 核 same-ELF SMP 执行 fp9 MoE forward
- duck 侧:persistent judge-step 返回结果
- host 侧:Rust 把结果通过 H2D 传回 GPU
- GPU 侧:进入下一层
在 MTP1 dual-lane overlap 模式下,token 0 的 stage1(duck 侧)和 token 1 的 stage0(GPU 侧)在时间上交错,不再串行等待。
11.6 结果证据
2026-04-08 测试档案(run_0408)
所有 7 组 case 的原始材料完整归档,见 测试档案页:
- 测试档案页:全部 7 组 case 的指标汇总、prompt/output、TPOT 图、逐 token CSV、原始 stdout/stderr 日志的入口
- manifest.tsv:所有 case 的
input_len / output_len / ttft / prefill / tpot / decode汇总表
2026-03-29 旧测试的关键日志节选
最终结果的完整 stdout/stderr 保存在:
stderr 末尾的典型 token 行输出:
Token # 1022: 3.742ms; value: next_token_ids=tensor([64], device='cuda:0')
mtp accept=1 prop=64 top1=64 accp=1.000
next=pair draft=25 prop=25 pred gate=device以及 pair overlap 摘要:
olap pair=111.1ms serial=197.3ms gain=86.1ms ratio=0.44 s0=5.7ms s1=191.6ms wait=0.2/44.2ms pred gate=device关键 commit
| commit | 说明 |
|---|---|
ab33e9e | fp9: prune dead common paths and land final 64/128 kernels |
d32c6fe | deepseek_v32: land MTP1 two-lane online path and trace-ready runtime |
279d749 | Enable persistent fp9 judge by default for decode forward |
e553d30 | Fix DeepSeek V3.2 flattened active_len and add critical tests |
11.7 结果口径说明
什么是 accept=1
MTP1 的 accept/reject 判断使用 sampling 策略:u * q(d) <= p(d),其中 q 是 draft 分布,p 是主干分布,u 是随机数。这种判断避免了除法操作,消除了不同精度下除法可能引入的数值差异。greedy 模式下简化为 d == argmax(p)。
为什么结果可信
这轮结果的三个支撑点:
- 正确性已通过:
02-prime-2k上accept=11813/2036的接受率在合理区间 - 549 个 step 的 overlap 摘要一致:
2026-03-29长跑不是”某次特别幸运地跑出好数字” - 多 case 读数相互印证:
2026-04-08的 7 组 case decode 大体稳定在13.7 ~ 16.3 tok/s这一档,不是单点异常 - 所有改动都在 active 代码路径上:没有 mock,没有 shortcut,没有跳过任何层
当前限制
- 质数查询 prompt 属于高接受率场景。在低接受率 prompt(如
"你好"约 70%)上,端到端 decode 提升有限 ~16 tok/s是 decode 吞吐,prefill 阶段在长 prompt 时略快,但没有达到商用 LLM 推理系统的级别- 当前只做了
max_model_len=2048以内的测试,更长的上下文还没系统验证 - 虽然已有多种 prompt 形态的 testcase,但仍不是标准 benchmark 套件(如 MMLU、HumanEval)
05-long-input-1的长 prompt 本质上是在复用项目自身的文稿,不等同于通用长文 benchmark
项目声明 / Project Disclaimer
本项目为作者以个人身份、利用业余时间推进的个人娱乐项目;除非另有明确说明,它与作者的任何雇主、客户、学校、单位或其他组织均无合作、雇佣、委托、赞助或背书关系,也不代表任何该等主体的立场。除普通个人捐赠外,本项目未获得任何资金支持。
This project is a personal hobby project developed by the author in a personal capacity and in personal time. Unless explicitly stated otherwise, it has no collaboration, employment, commission, sponsorship, endorsement, or institutional affiliation with any employer, client, school, partner organization, or other entity, and it does not represent any such party's views. No funding was received for this project except ordinary personal donations.
许可 / License
除非另有说明,本页原创文字、本站原创图片与本站原创图表采用 CC BY-NC-ND 4.0 发布。
转载时请保留原文标题、署名“JudgeDuck AI”、发布日期与原始链接;禁止商业转载、改写、摘编、翻译或基于原文创作演绎作品。
第三方商标、外部链接内容,以及文中另有标注的材料,不在上述许可范围内。
Unless otherwise noted, the original text, original images, and original figures on this page are licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.