一鸭三吃:我把评测鸭变成了满血 DeepSeek-V3.2 推理系统
这不是为了融资或产品化而造的系统,而是一个从评测鸭、远端执行器和个人好奇心一路长出来的异构推理项目,最后真的把满血 DeepSeek-V3.2 跑到了可用速度。
先把最终结果摆出来
1 × RTX 5090 + 32 × Intel N100,运行 DeepSeek-V3.2(685B 参数,含 MTP head)。
到 2026 年 4 月,系统已经跑过一组共 7 个 testcase,涵盖短 prompt 长输出、长 prompt 中等输出、极短问候等多种场景。其中 02-prime-2k(prompt:104857601是质数吗,2037 tokens 输出)decode 达到 16.171 tok/s。另一条代表性 case 05-long-input-1(包含本项目技术报告的长 prompt,1481 tokens 输入)decode 达到 14.206 tok/s。
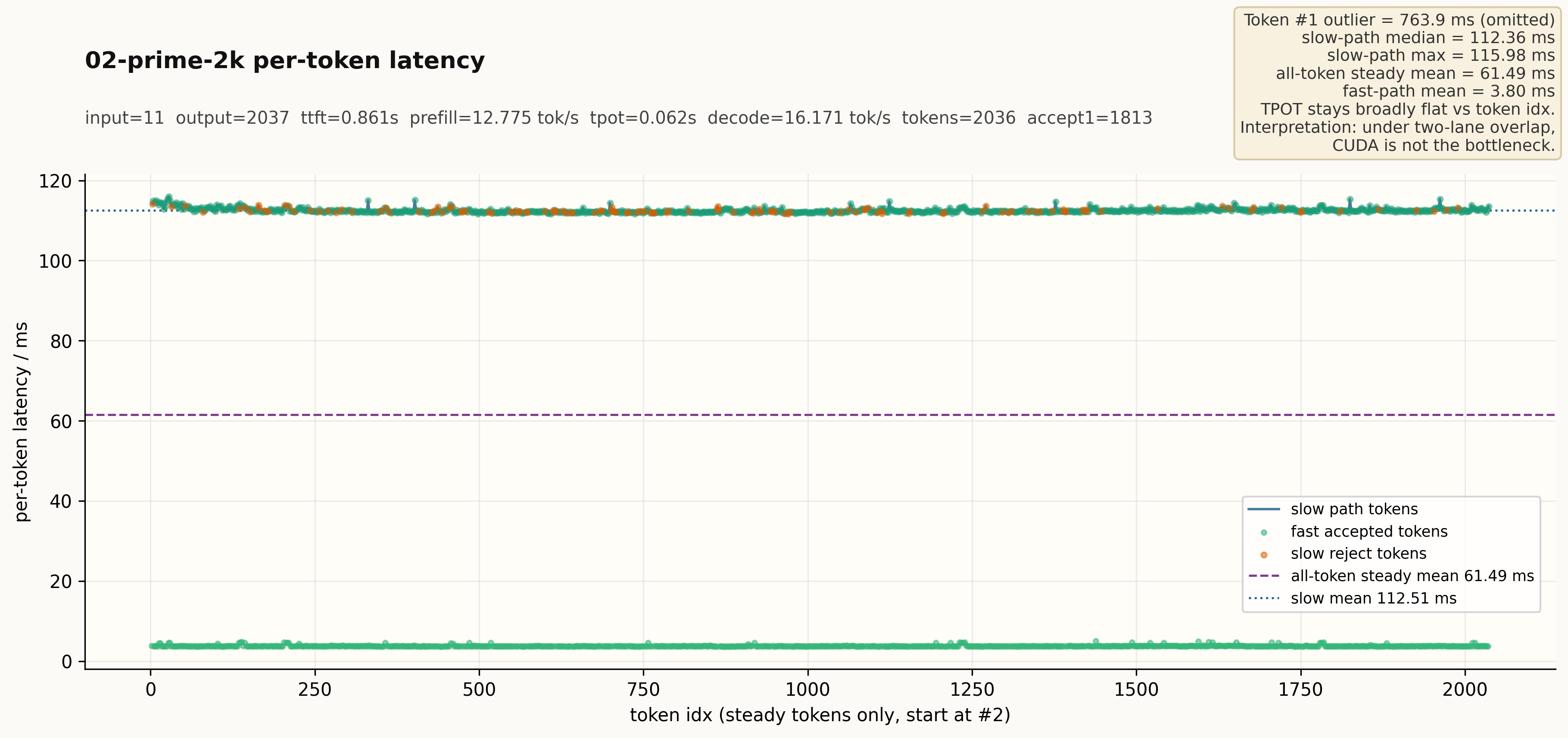
图:02-prime-2k 逐 token 延迟分布。slow path 中位约 112 ms,fast path 平均约 3.8 ms,CUDA 不是瓶颈。
这两个数字意味着什么?对于一个本地部署的 chatbot 来说,14~16 tok/s 已经达到了“基本可用”的水平——你问它一个问题,它以接近人类阅读速度往屏幕上吐字,不会让你等得太难受。这不是什么 SaaS 级的并发性能,但作为一台工作机带 32 台小盒子跑 685B 参数的模型,它已经不是“能跑”而是“能用”了。
这不是理论峰值,不是 mock 路径,也没有跳过任何一层。stdout 和 stderr 完整证据保存在报告附录里。所有 7 组 testcase 的逐 token CSV 和 TPOT 图均完整归档。
但这件事其实不是从大模型开始的,而是从评测鸭和远端执行器开始的。
这件事不是从大模型开始的,而是从评测鸭开始的
2024 年 12 月,我采购了一批 Intel N100 准系统——下单规模是 100 台准系统 + 100 条 32 GB DDR4-3200 内存。当时的出发点是给评测鸭 / JudgeDuck(在线评测网站,GitHub)扩容评测机。评测机运行自制的操作系统 JudgeDuck-OS——跟大模型没有任何关系。
N100 这颗芯片在公共舆论里没什么好名声。它是一颗 6W TDP、4 个 E-core(Alder Lake-N,Gracemont 系)、单通道内存的低功耗小核 x86,Intel ARK 上的规格看起来就像是“什么正经事也干不了”。2025 年甚至有人在公共社区质疑 N100 不适合作为评测节点,焦点集中在散热、降频、缓存和 32 GB 配置的合理性上——公共直觉常把它看成“配置极低、不可靠”。
我的观察是,经过 BIOS 调教(调整 Turbo Ratio Limit、开放 PL1/PL2)之后,N100 单核跑到官方标称的 3.4 GHz 没有问题,全核持续负载下也能稳在 2.9 GHz 左右。而当时给每台鸭配 32 GB DDR4-3200,纯粹是因为“反正内存不贵,多给点没坏处”,并不是为了任何 LLM 路线。
这批鸭子从采购到装机,是手工活:

图:2025 年 1 月初,鸭子装机现场。
它们被部署成 JudgeDuck-OS 的远端执行节点——通过网络 PXE 启动,载入用户 ELF,计时,返回结果。每台鸭子不跑通用 Linux,没有 glibc,没有常规进程管理,就是一个最小化 x86-64 内核加上沙箱 ELF 执行。这个流程对评测来说够用。
到这时候,host 机器和鸭子群也完全没有关联。host 是 2023 年自费购置的主力工作机,i9-13900K + 128 GB DDR5,用于日常科研和开发。买它的时候,鸭群还不存在。
图:host 机器装机阶段的 memtest86 跑分,内存 4×32GB DDR5 稳定通过。
两批硬件之间没有预设的联系。直到后来,有人把它们放在一起想了一遍。
真正埋下伏笔的是内存;R1 之后,问题第一次被改写
DeepSeek-R1 公开之后,我第一次认真把问题写成了“能不能本地跑满血 685B”。
这个想法的出发点不是框架选型,不是论文阅读,而是容量、带宽和 roofline 的粗算。
先算容量。DeepSeek-V3 系列的官方发布格式本身就是 fp8,完整权重在磁盘上约 688 GB。32 只鸭子合计 32 × 32 GB ≈ 1 TB 总内存,看起来似乎装得下——但要留内存给 OS、ELF、input/output buffer,实际可用并没有那么宽裕。
再算带宽。每台 N100 的 DDR4-3200 单通道理论带宽约 25.6 GB/s,32 台合计约 819 GB/s。而一张 RTX 5090 的显存带宽约 1792 GB/s,高于鸭子侧的总量。
这两组数字放在一起,一个自然的分工就浮现出来了:
- Attention 相关参数(KV cache、MLA 低秩矩阵、attention projection)可以被 5090 的 32 GB 显存装下——集中在 GPU 上处理。
- FFN/MoE 专家层的权重远超单机显存容量——分散到 32 台鸭子的总内存里。
这个分工被称为 AFD(Attention-FeedForward Disaggregation)。我是按自己的容量和带宽约束独立推到了这套切分,后来补查时发现外部已经有人讨论过类似思路,并被概括为 AFD 这个名字——知乎专栏、Emergent Mind、甚至有 TensorRT-LLM 的 AFD 特性提案。清华大学趋境团队的 kTransformers(SOSP 2025)也是 AFD + CPU/GPU 混合计算——把 Attention/Shared Expert 留在 GPU,把 Routed Expert 卸载到同一台服务器的 CPU 上,利用服务器 CPU 的大内存带宽来做 MoE 计算。而我的路线是把 FFN/MoE 拆到 32 台独立的小机器上,用以太网做通信。多了一层网络,通信压力完全不一样。
选 5090 也不是靠榜单选出来的。核心判断只有两条:32 GB 显存能装下 Attention 侧工作集,且 1792 GB/s 显存带宽明显高于鸭子侧的理论总量。

图:host 机箱当前状态,额外竖起的风扇是为给 E810-XXVDA4 网卡(4 口)散热加装的。
2026 年 2 月初,5090 到货安装到位。同一时间,网络拓扑也从之前的 10GbE 阶段整体升级到了 25GbE——一张 Intel E810-XXVDA4 网卡(4 口,Intel E810-C 芯片,系统识别为 4 个独立 NIC)、一台 48×2.5GbE + 4×25G uplink 的交换机。5090 的选型和到位,早于 Qwen3.5 适配约六周。这张卡是按照 AFD 的系统思路主动选出来的,而不是“接了新模型之后才决定买卡”。单卡 4 口塞进机箱后发热不小,额外竖起了一个风扇专门给它散热。

图:4 组鸭子集群的物理布局。每组 8 台 N100,共 32 台。中间是 48 口 2.5G 交换机,接入了 4 个 25G 上联。
外部语境也让这条路线显得更有现实意义。2026 年一季度,TrendForce 在 2 月和 3 月两次公告里都把 DRAM / NAND 涨价预期继续上修(2026-02-02、2026-03-03),Micron 也在 2025 年底宣布退出 Crucial 消费者业务(来源)。单机大内存路线的成本和供给正在变得更不稳定,这反过来让“用一批小机器拼出大内存”这件事显得不那么像私人怪癖。
真正难的不是把参数塞下,而是通信
有了 AFD 的分工方向之后,下一个问题很快就浮出了水面:网络。
先把并行策略选出来。pipeline parallel 不减少单 token 的端到端延迟,只是把参数体积切成多段;expert parallel 可以切 MoE 的专家参数,但 bsz=1 的时候 routed experts 的选取是不确定的,不能稳定加速。所以最终选的是 tensor parallel——模型被切开后每只鸭算得更少,单 token 的延迟确实能降下来。
但 tp 的隐藏成本很直接:在数据中心里它靠 NVLink 或 InfiniBand 做每层的全收集/全分发;对这套纯以太网的系统来说,每次 reduce 都要在网络上传输大量中间激活值,每 token 的网络传输时间就成了需要着重优化的对象。
这就是为什么 host 上联成了执念:在这套系统里,每个 token 都要走完 GPU → 网络 → 鸭子 → 网络 → GPU 的全链路,整条链被最慢的环节拖着走。所以 2.5GbE 的意义不在于堆出更大的总吞吐,而在于把单个 token 的序列化时间从 15ms 压到 6ms——是延迟问题,不是带宽问题。
更早的时候,鸭子用的是 1GbE 链路。2025 年 2 月 16 日,我补了两台 H3C S1850V2-28X 交换机(各带 4 口 10G 上联),意识到 1G 上联不够,第一反应是“至少先把 10G 上了”。2025 年 2 月 25 日试了一块华为 SP570 25G 四口卡——价格便宜但实物很烫,驱动无法正确初始化,dmesg 里一堆报错。三天后(2025-02-28)改买 Intel X520-DA4(82599 芯片),一次点亮。到 2025 年 10 月搬家后,10G ×4 拓扑才正式把 32 只鸭子全部接起来,变成真实在役的集群形态。
这条 10G 阶段持续了大约五个月。2026 年 2 月,网络拓扑整体升级到了 25GbE——一张 Intel E810-XXVDA4 网卡(4 口,E810-C 芯片,系统识别为 4 个独立 NIC)、一台 48×2.5GbE + 4×25G uplink 的交换机。
网络演化不是一步到位的。它是一条从“能不能都连上”,到“回包能不能同时被收到”,再到“每 token 能不能快一点”的连贯路径:
- 连通阶段(2025-02 ~ 2025-10):2025 年 2 月 16 日补了两台 H3C S1850V2-28X 交换机(各 4 口 10G 上联),试了华为 SP570 失败后改买 Intel X520-DA4(82599 芯片),到 2025 年 10 月搬家后正式搭起 10G ×4 拓扑,32 只鸭子全部在线。
- 调度阶段(2025-10 ~ 2025-12):连通之后才发现,Linux 内核网络栈处理 32 只鸭子同时回包时有不可预测的调度延迟。从 socket 复用、async Rust、sendmmsg/recvmmsg 一路试到 breakdown 分析,最终在 2025 年 11 月底决定学 DPDK,12 月初 DPDK worker 正式接管收发。
- 速率升级阶段(2026-02):2026 年 2 月 10 日同时下单 25G 交换机和 E810-XXVDA4 网卡,把鸭子从 1GbE 升到 2.5GbE,host 上联从 10G ×4 升到 25G ×4。核心动机不是堆吞吐,而是把每 token 的序列化时间从 15ms 压到 6ms。
每个广播域里,host 的 IP 分别是 10.21.1.1 到 10.21.4.1,32 只鸭子的 IP 分布在 10.21.[1-4].101~108。4 个独立广播域意味着 4 个 DPDK worker 可以独立占用自己的 NIC,互不干扰——这个设计后来被证明是对的。
网络升级只是基础设施。真正的通信栈,还需要从应用层一路被逼下来。
在只有 AVX2 的 N100 上,我先做出了单核 MLP fp9
fp9 是这个项目里技术含金量最高的个人发明之一。
它的起点不在 DPDK,不在网络层,而是在 2025 年 8 月底,研究如何在 N100 上最高效地做 fp8 → fp32 批量乘法时。
N100 只有 AVX2 + FMA,没有 AVX-512,没有原生 BF16 指令。最直观的做法是用 bf16 或 fp16 存权重——但 N100 上没有原生的 bf16 GEMV 指令,做 bf16 推理时需要先把 bf16 展开成 fp32 再参与乘加,等于把计算量翻倍,而且带宽压力并没有减轻:付出了 16-bit 存储的代价,计算时却得升到 32-bit。换成 fp8 存储可以把读权重的带宽需求砍一半,但 fp8 解码涉及位操作、移位、指数偏置计算,每次乘加前都要先做一次格式转换,如果转换做得不够快,省下来的带宽优势会被转换本身的 latency 吃掉。
在这个讨论过程中,想到了一个替代方案:与其去处理 fp8 decode 的各种边界情况,不如在设计格式时就让 decode 路径本身变得直接。fp9 就是在这个思路下被提出来的——不是 AI 给出的方案,而是研究已有格式的问题时自己想出来的,后续才让 AI 分析它在位级实现上是否可行。
核心权衡一句话:多用 12.5% 的存储空间,换取 fp9 → fp32 decode 路径的大幅提速。
fp9 的 9 个 bit 分三段:符号位 1 bit、指数 5 bit(偏置 15)、尾数 3 bit:
bit 8 bit 7..3 bit 2..0
s eeeee mmm
(符号) (指数, 5位) (尾数, 3位)指数偏置选 15 不是随便定的——和 IEEE fp16 的指数偏置完全一致。这让整个 decode 路径可以和现有硬件指令自然对齐。实际存储时,fp9 被拆成主体字节(去掉符号位后的 8 bit)和符号平面(每 8 个权重的符号位打包成 1 字节,存在并行数组里)。8 个权重占 8 + 1 = 9 字节,正好 9 bits/value,比 fp8 多 12.5%。
decode 的路径因此变得出奇地直接:用 SIMD 把主体字节零扩展为 uint16,把 sign plane 里的符号位展开成 mask 做 XOR,然后左移 7 位——恰好成为合法的 fp16 格式——直接交给 f16c 硬件指令转成 fp32。整个过程不需要额外的 exponent 修正逻辑,连 +0 / -0 也能自然处理正确。
2025 年 8 月底,fp9 已经被放进了真实 forward 路径。当时 duck 侧先承担单核 dense MLP forward,从 8 月 30 日晚间的约 7 ms,一路压到 8 月 31 日下午的 2.45 ms。更关键的是,8 月 31 日傍晚已经出现了一组判断:单次实际运行约 2.45 ms,但端到端仍在 12 ms 左右。这说明 fp9 第一版的单核 MLP 本体已经先跑出来了,随后暴露出来的主矛盾反而是 JudgeDuck-OS 一侧的固定成本。
JudgeDuck-OS 真正被重审,是因为它突然变成了 launch runtime
触发点:算力已经够了,开销却还在
2025 年 8 月 31 日傍晚,这 11.5 ms 被明确拆了出来。问题是——“这次算完”到“下一步能开始”之间要等将近 10 ms,中间那段空白去哪了?
这是第一次按 launch latency 的视角去重审 JudgeDuck-OS。
为什么一开始不做成常驻服务,避免频繁 launch
原因很务实:在已有的评测场景下,一道题本来就要跑几百毫秒,launch 花掉的几毫秒被摊薄到不值一提。而且 JudgeDuck-OS 的原始抽象“给一个 ELF,跑完就退出”有一个非常实在的优点——它是一个被长期使用过的沙箱,程序在里面挂掉不会顺手把整台鸭子搞坏。
把它做成常驻服务意味着要给 userspace 打开网络接口,或者重新发明一套 syscall / IO 机制;做成 kernel 内常驻程序则意味着一旦写错更容易把整台机器直接打崩。所以早期并不是没想到 persistent,而是在“稳”和“快”之间,评测场景天然选了稳。
但当 compute 被压到 2.45 ms 而 launch 依然吃掉 11.5 ms 时,“稳”不再是一个合理的借口了。
一天之内,五个提交
2025 年 8 月 31 日当天,仓库里连续落了五个提交,每处都对应一项具体可见的开销:
| 提交 | 解决的问题 | 具体做了什么 |
|---|---|---|
Fast ELF loading (6f249af) | load elf 约 5 ms | 只刷新页表差量,不再对整段物理内存刷新标志位 |
Load IB by memory-map (7f2d1eb) | memcpy/IB 约 3 ms | 页对齐后直接 mmap,跳过 memcpy 把输入 buffer 拷进 IB |
Skip wbinvd (a3ea37c) | syscall return 约 0.4 ms | 去掉 syscall return 路径上的 wbinvd(全 cache 刷回并失效) |
Update scheduler config (44c8c7e) | idle → sleep 误入唤醒 | idle 阈值从 1 ms 改为 10 ms,duck 停留在 polling 而非反复 sleep/wake |
Enable AVX (bbf244f) | 后续 SIMD 优化的前提 | 让 N100 的 AVX 指令集真正可用 |
一周后(2025-09-07),又补了 Update buffer/cache config,把 buffer cache 上限从 4 GiB 一路拉到 32 GiB,让 JudgeDuck-OS 的 buffer 分配策略适配真实的 duck forward workload。
这次重审的意义
不是“过去都错了,后来才变对”——JudgeDuck-OS 原有的抽象边界有其合理性,后来继续压成本时才需要继续改造。
它开始从“单次评测 OS”转向“低延迟远端 runtime”。但此时多核执行能力还没有真正做出来,常驻会话也还没有出现。系统首先完成的,是把单次启动路径里最显眼的固定成本打掉。
userspace 网络终于把系统逼成了“一鸭三吃”
DPDK 不是一开始就想上的。它是可量化数据一路推过来的最后一步。
从 socket 复用开始
最早暴露的问题是 socket 复用。每次为每个请求新建一个 UDP socket、用完关掉,在高频调用场景下很快会耗尽端口资源。修复思路直接:把每个 duck IP 对应的 socket 缓存到全局 map 里复用。修完之后系统至少能稳定运行了——但这只是“能跑”,还不是“能用”。
2025 年 10 月 1 日前后,第一次认真量了 forward 的端到端时间。当时用的是多线程模式:每只 duck 对应一个线程。观察到的现象是——14 只鸭子的第一次发送完成时间,能差到 0.35 ms。仅仅是“开始发包”这个操作,自己就能拉开 0.2 ~ 0.3 ms。
对于一个目标在 2.5 ms 左右的 MLP forward,光是发包就能让鸭子们差出 10% ~ 15%。诊断很清楚:每个线程在自己的 busy loop 里等,而 Linux 内核时间片的分配让这些线程不会精确地同时调度上 CPU。
这是后来切换到 async Rust 的真实动机:不是语言风格偏好,而是想把“每鸭一个忙等线程”改成事件驱动的异步调度。
recvmmsg/sendmmsg:userspace 路径的最后一步
2025 年 10 月 18 日,recvmmsg 跑通了 POC:
图:recvmmsg POC 跑通时的截图,2025-10-18。
Linux recvmmsg / sendmmsg 允许单次 syscall 收/发多个消息——把“32 次 syscall 收 32 个响应”变成“1 次 syscall 收最多 32 个响应”。在转向 DPDK 之前,这已经是“单包单 syscall”路径上能做的最后一步优化。
到 2025-11-30 的 d8a1248 non-dpdk baseline 提交,Rust 主线里已经有完整的 async broadcast + sendmmsg / recvmmsg_batch 实现。也就是说,在转向 DPDK 之前,已经做过了一轮很认真的批量 syscall 优化。
用 breakdown 看清 syscall 墙
2025 年 10 月 19 日,做了一批系统性的 breakdown 测试:
| 场景 | duck forward 本体 | Rust 端到端 |
|---|---|---|
| 0.6B tp24 | 约 109 ~ 112 µs | 约 546 µs |
| 大 payload 档位 | 约 3.02 ms | 约 4.277 ms |
大 payload 下,send 和 recv 各自都有约 0.47 ~ 0.49 ms 的额外成本。更直接的一个指标是:duck 侧第一个 ACK 到最后一个 ACK 的时间跨度约 160 µs,但 host 侧的 recv 时间窗口却被拉到 200 µs 以上。
duck 端已经“同时”算完并回包了,host 端却还没全部收到——这就是所谓的 "duck stampede"(鸭群踩踏):duck 们几乎同时发回 UDP 包,但 host 的 Linux 内核网络栈在处理这批同时到达的包时引入了不可预测的调度延迟。
这时候问题的性质已经很清楚了:不是 duck 算得慢,也不是批量 syscall 不够聪明,而是 host 的内核网络栈本身就不适合处理这种“32 只 duck 几乎同时回包”的模式。
DPDK 和三层结构
2025 年 11 月 23 日,这条线收束到一个明确的判断:必须认真学 DPDK。
DPDK 的核心机制是让用户态程序直接轮询 NIC 的 RX/TX descriptor ring,完全绕过 Linux 内核的中断处理和调度器。网卡收到包不是中断 CPU,而是 CPU 主动去 descriptor ring 里取。
在这个阶段,甚至认真考虑过“能不能用 Rust 的 DPDK 绑定来做”。社区里确实存在一些 Rust DPDK 的尝试,但评估后的结论很明确:DPDK 的官方、稳定、被大规模验证的路径在 C++(libdpdk),而 Rust 绑定在 API 覆盖度、版本同步和调试工具链上还不够成熟。
于是最终定下了三层分工:
- Python 层:模型计算逻辑和调度决策,不直接接触网络包
- Rust 层:duck 状态管理、forward 编排、buffer 管理,通过 FFI 调用 C++ DPDK
- C++ DPDK 层:每张 NIC 一个 worker 线程,绑定独立 lcore,热路径完全在 userspace
到 2025-12-05 的 6fb5308 dpdk initialization and fast ipc,DPDK 不再只是试验代码,它开始成为系统的实际收发骨架。2026 年 3 月真实系统日志里看到的启动序列:
[2026-03-09 01:06:48.038508 INFO dpdk_workers] DPDK initialized successfully. Found 4 ports.
[2026-03-09 01:06:48.038537 INFO dpdk_workers] Starting worker #0:
(bcast_ip: 10.21.1.255, port_id: 0, lcore_id: 2, host_ip: 10.21.1.1)
[2026-03-09 01:06:48.038577 INFO dpdk_workers] Starting worker #1:
(bcast_ip: 10.21.2.255, port_id: 1, lcore_id: 4, host_ip: 10.21.2.1)4 个 worker 分别绑定在 lcore 2、4、6、8,对应 E810-XXVDA4 网卡的 4 个独立 NIC 端口。
回头看这条演化路线:先修 socket 复用,再转 async 调度,再上批量 syscall,最后用 breakdown 看清内核网络栈本身是障碍。到了这一步,改用 DPDK 就不再像一次冒险,而更像顺着问题本身走到的结果。
“一鸭三吃”——同一只 duck 节点,在 host 上被三层软件同时使用:Python 层发起模型计算请求,Rust 层管理它的状态和编排,C++ DPDK 层处理它的网络流量。而 duck 本身只运行 JudgeDuck-OS 和 fp9 kernels,没有 Linux,没有 glibc。
AI 没替我做判断,但它确实改变了推进速度
项目一度卡在通信栈上,不想写。Linux 内核网络栈的调度延迟始终压不下来,userspace socket 路径只有 ~10Gbps,多进程也不行,sendmmsg/recvmmsg 做到极致还是被内核打断断点。breakdown 分析、kernel 调优 harness、大量日志里的时间戳模式——这类工程体力活积累到一定程度之后,人的主观意愿也掉到了谷底。
Codex 出现之后,推进速度暴涨。AI 帮我把最苦的 DPDK 链路部分补掉——写 C++ DPDK 的 boilerplate、分析位级方案是否可行、在海量日志里找规律。我自己的主观感受是:Codex + 人类强控制,把这个阶段的推进效率拉高了至少 10 倍。项目从“卡在网络不想碰”迅速推进到了“一鸭三吃”的三层结构定型。
当然,AI 没有替我做关键架构判断。fp9 的位布局是自己想出来的,AFD 的分工是摆着约束算出来的,DPDK 的三层结构是 breakdown 数据逼出来的——这些不是 AI 给的方案。AI 回答的是“这条路怎么走”,不是“这条路值不值得走”。
另一个意外收获是 Rust。我原本对 Rust 不算熟:记不住常见写法,也不容易快速读懂别人的代码。但项目的关键部分必须上 Rust,于是我采用了一种有时代感的学习方式——不等自己“系统学完再开工”,也不依赖 language server,直接让 ChatGPT 解释每一个编译错误。通过不断处理真实编译错误,很快拟合出了自己对 Rust type system 和 borrow checking 的理解。2025 年 10 月那阵子,我每天都在密集地问 Rust 异步编程和 Tokio 的问题,到 11 月底 non-dpdk baseline 提交时,Rust 已经是仓库的活跃主体。
先用 Qwen3 练级,再让 Qwen3.5 充当高压试炼场
在碰 DeepSeek-V3.2 之前,系统需要练手。Qwen3 系列提供了从 0.6B 到 235B 的完整规模梯度,而且它的官方 fp8 checkpoint 用了与 DeepSeek-V3 相同的 128×128 block-scale 格式——格式兼容,规模更小,适合先行验证。
Qwen3:把整条链路跑通
duck-llm 的第一个 commit 是 2025 年 8 月 3 日。最开始是纯 PyTorch 实现,能在 CPU 上跑通 Qwen3-0.6B,duck 节点完全不在场。目的只有一个——把模型结构、权重加载、generation loop 这些骨架搭对。
到 2026 年 3 月 9 日,Qwen3 MoE 原生 duck 支持提交进仓库。在 Qwen3-30B-A3B-FP8 上拿到了第一批 MoE decode 数据:tp=12 时约 13 tok/s,tp=24 时约 18 tok/s(eager 模式)。
同一时期,sub-128(multiple_of=64/32)落地,解锁了更高的 tp 点位。对 30B 来说,从 tp=6 的 8.7 tok/s 一路拉到 tp=24 的 17.4 tok/s。
5090 先到,Qwen3.5 是高压试炼场
2026 年 2 月初 5090 到货,这是按照 AFD 的系统思路主动选出来的——duck 节点承载 MoE/FFN,5090 承载 Attention 侧。Qwen3.5 和随后的 DeepSeek-V3.2,都是在 AFD 路线已经成型之后,作为更大规模的高压试炼场被接进来的。
2026 年 3 月 17 日开始 Qwen3.5 适配。调查结果显示:它不能按“给现有 qwen3 改几处 config 字段”来接。真正的变化有四层——顶层架构变成了 vision + text 双配置、hybrid attention(linear 和 full 交错)、zero-centered RMSNorm、gated full attention。
基于这些差异,决定新建独立目录 duck_llm/models/qwen3_5/,完全独立实现。
首批真实结果很直接地说明了系统的成熟度:
Qwen3.5-35B-A3B-FP8(tp=16):decode 20.601 tok/sQwen3.5-122B-A10B-FP8(tp=16):decode 11.615 tok/s
两条路线都能输出语义连贯的中文回复。这也印证了同一套 Rust ABI 和 fp9 kernel 能承接结构差异显著的模型家族。
常规优化把系统推进到“终于像样”,但还不够
Qwen3 练级期间,一大批固定成本压缩的改动陆续落地。这些不是小修小补,而是把系统从“能跑”推进到“像样”的连续动作。
非 duck 那段时间去了哪里
2026 年 3 月 12 日,调试 Qwen3-30B-A3B-FP8 的 MoE decode 时发现一个值得追查的现象:即便 MoE duck forward 本体已经明显变快,端到端的 decode TPS 并没有按比例提升。
粗算之后的数字很清楚:decode 约 77ms/token,duck 侧 judge_wait 合计约 47.8ms,剩下约 29ms 不在 duck 里。其中 attention 的 torch.cat KV cache 追加是最大的单项。
这个发现直接驱动了后续一连串改动。
一组连续动作
这轮优化涉及七处改动,时间集中在 2026 年 3 月中下旬:
| 改动 | 日期 | 效果 |
|---|---|---|
| flash attention 2 + 静态 KV cache | 03-14 | 预分配 KV cache buffer,为后续 CUDA Graph 提供固定形状 |
| flattened decode runtime | 03-14 | 30B: 18 → 24 tok/s (+33%) 235B: 4.3 → 4.7 tok/s 非 duck GPU 时间 0.44 → 0.20ms/layer (-55%) |
| same-ELF SMP 多核 | 03-16 | 235B: 4.7 → 约 9.0 tok/s (约 1.9x) |
| weight cache | 03-18 | 每次 prepare 向 32 台鸭分发约 700 GiB 权重的问题被跳过 开发体验从“改一行等几分钟”变成“秒级重启” |
| Triton fp8 路径 | 03-20 | 修掉 V3.2 61 层 OOM 权重保持 FP8 常驻 显存节约约 2435 MiB |
| split128 decode context 内核 | 03-21 | V3.2 TPOT 降到约 161 ms |
| persistent judge | 03-23 | judge_gap 418µs → 78µs (-5x) V3.2 TPOT 137ms → 110ms decode 7.30 → 9.09 tok/s |
其中 flattened decode runtime 还有一个值得记一笔的插曲:上线后立刻遇到典型的“第二次才坏”的 bug——第一轮对话输出正常,第二轮输出乱码。根因是 graph 复用时绕过了 decode state 刷新,修法是在 generate() 入口统一重置状态,KV cache 扩容时丢弃所有已 capture 的 graph。
到这个时候,系统已经从“勉强跑通约 3 tok/s”推进到“接近 10 tok/s,各项机制基本像样”。但真正的突破还在后面。
真正的突破来自 MTP1 dual-lane overlap
MTP(Multi-Token Prediction)和 speculative decoding 本身是公开技术,DeepSeek-V3 的技术报告明确把它写成了推理加速的方向。vLLM 的文档也把它列为受支持的方法之一。GPU serving 世界里还有 two-batch overlap 那种计算/通信重叠思想——把请求拆成 micro-batches,交错执行不同阶段。
但在这套 cuda + duck(tp32) 的异构系统里,MTP 该怎么做,并没有现成答案。
两条路线
在系统跑通 duck tp32 之后,认真想了一下,发现 MTP 有两条可执行的路线。
路线一:cuda bsz=2 + duck (tp32)×2。CUDA 侧很容易支持一次 forward 两个 token,duck 侧最自然的部署方式是直接上两组鸭——64 台。但代价是需要再上架 32 台鸭子、额外交换机端口、布线、安装配置,以及把 host uplink / PCIe / 内存带宽重新推回高风险区间。
后来回看,2025 年想 duck tensor parallel 的时候,我已经隐约想到过这条路线,但当时意识到 MoE 专家路由近似随机、两组大概率不重叠,没有继续往实现层推。
路线二:不加机器,做 dual-lane overlap。这里有一个关键观察:现在系统里每层 decode 的流程是 cuda → duck,这两段用的是完全不同的资源——CUDA 用的是 GPU 算力和 GDDR7,duck 用的是 CPU + DDR4 + 网络带宽。它们在时间上是串行的,但逻辑上没有理由必须串行。
对两个 token 来说,如果像流水线一样把两种资源尽量叠起来:
token0: [cuda0] [duck0] [cuda1] [duck1] ... [cuda60] [duck60]
token1: [cuda0] [duck0] [cuda1] [duck1] ... [cuda60] [duck60]理想情况下,pair 时间的下界约 2 × max(cuda_per_layer, duck_per_layer),而不是串行时的 2 × (cuda + duck)。真实系统里 duck 时间约占 cuda + duck 的 70%,接受率约 80%~90%,代入公式理想加速比约 1.32x。
这条推导和 two-batch overlap 那种抽象思想是相通的——都是把两类原本串行的资源尽量重叠起来。但具体技术上是不同的实现:那里重叠的是通信和计算,这里重叠的是 GPU 和网络/CPU。
为什么不选路线一
路线一不只是“多买 32 个鸭”的问题。交换机端口、布线、安装、配置与 bring-up 的现实成本加在一起,同时也会把 host uplink / PCIe / 内存带宽重新推回高风险区间。路线二不需要额外采购设备,也没有这些风险。后来路线二已经把系统推到 15 tok/s 一档,加机器的动力也没有那么强了。
落地
2026-03-29 的一次 1024 tokens 长跑给出了证据:549 条 overlap 样本的统计均值,pair 约 112ms,serial 假设约 199ms,gain 约 86ms,ratio 约 0.434。这意味着 dual-lane overlap 稳定地把双 token 的总时间压到了串行时间的约 57%。
脏现实终于全面追上主线,而结果终于可以公开
到真要跑 DeepSeek-V3.2 tp32 的时候,物理世界的问题第一次卡住了主线。
- “失忆鸭”:有几台鸭子的 BIOS 电池(CR1220)耗尽,可以响应 magic packet 唤醒,但不再按预期进入 PXE 启动。
- “坏鸭”:个别节点工作异常,经检查发现是“内存没插好”。
- 还有“网线没插好”——这种级别的错误在任何论文里都不会出现,但在这套系统里,它真的会让 decode 速度掉一截。
tp31 的时候还能勉强继续推进,但到 tp32,每一只鸭都开始重要。2025 年 10 月时勉强能用 tp31 凑合的日子过去了——真要跑满血 V3.2,32 台都得在线。
这些细节把系统从“看起来很抽象”的架构图拉回了地面——其实你是在修一堆真的小机器。
最终结果
02-prime-2k:
Generation stats: time 126.724s, input_len 11, output_len 2037,
ttft 0.861s, tpot 0.062s, prefill 12.775 tok/s, decode 16.171 tok/s
05-long-input-1:
Generation stats: time 114.782s, input_len 1481, output_len 567,
ttft 74.499s, tpot 0.070s, prefill 19.880 tok/s, decode 14.206 tok/sMTP1 accept=1 在 02-prime-2k 上约 89%(1813/2036)。
这个结果是 MTP1 dual-lane overlap、persistent judge、final fp9 kernels、lm_head 优化、predictive build 等多项改动共同累积的结果。persistent judge 落地后的基准约 9 tok/s,MTP1 online 早期版约 14 tok/s,最终随所有改动落定到 15.3 tok/s(2026-03-29,1024 tokens),后续 2026-04-08 的多 testcase 补跑进一步确认 decode 稳定在 13.7 ~ 16.3 tok/s 这一档。
限制条件
这里不要只报喜:
- 质数查询 prompt 属于高接受率场景。在低接受率 prompt(如
"你好"约 70%)上,端到端 decode 提升有限 - 当前只做了
max_model_len=2048以内的测试,更长的上下文需要实现 sparse indexer,而 RTX 5090(sm_120)上的 MLA attention backend 支持还不完整 - 虽然已有多种 prompt 形态的 testcase,但仍不是标准 benchmark 套件
05-long-input-1的长 prompt 本质上是在复用项目自身的文稿,不等同于通用长文 benchmark- 多轮对话的增量 prefill 和会话级 KV cache 还没有做成正式能力
- fp9 prefill kernel 的性能还远未达到 N100 的理论算力上限
16 tok/s 之后:一段没有跑通的路
跑到 16 tok/s 的那一刻,系统其实已经“够用”了。但够用之后,一个很自然的问题冒了出来——还能不能再快一点?
当时的分析很具体。看一次 MoE forward 的 breakdown:
MoE forward e2e time (Rust): 975.231µs
prepare=3.036µs, send=60.612µs, judge_wait=782.597µs,
fetch=91.729µs, reduce=20ns, writeback=544ns
duck time-ns stats: p50=697.975µs
judge_gap=75.804µsduck 实际计算约 698 µs,但 judge_wait 占了约 783 µs——两者之间差了大约 85 µs,再加上 fetch 的 92 µs、send 的 61 µs,整个 forward (975 µs) 里大约有四分之一的时间并非在 duck 上算,而是通信和同步的固定成本。换句话说,即使把 compute 本身压到零,这些 overhead 还在那里。
那能不能让 duck 一个一个 token 地 back-to-back 计算,把通信的时间重叠到计算里面去?
于是有了 daemon 这轮尝试。
思路并不激进:不走 IRQ 和中断,不跳到完整 userspace 协议栈,只是在 duck 侧放一个常驻的小 daemon,host 侧在计算的同时发 poll,尽量把“等”的时间叠进“算”的时间里。在 Qwen3-30B 上试的时候,daemon 的 poll 开销一度压到了每步约 4 µs——看起来好像真的有戏。
但 correctness 线没有站住。prepare 看似成功了,随后 metadata 的 write-buffer 稳定在一个异常值,duck 进入了“半死但未彻底掉线”的不可服务状态。多个问题叠在一起——lifecycle 和 close 语义怎么定义、host 和 OS 的 ABI 对齐、bring-up 和 stale daemon 的清扫、core0 的 straggler 行为——每一个单拿出来都不是大问题,但凑在一起就没法同时解决。最终两个仓库都做了 checkpoint,然后回退到了 daemon 之前的正确基线。
这轮尝试的结果是:没有跑通。但它不是白跑——把 poll 下沉进 compute-time path 这件事本身并非没有收益,只是从“能 work”到“能交付”的跨度比预想的大。这条线保留为一次有价值但未落地的尝试,没有纳入当前正式结果。
同一时间段,系统补跑了一组 7 个 testcase 的完整档案——这就是上面两条代表性 case 的来源。
这件事明明可以做成一个产品,但我还是想把它留在“个人娱乐项目”这个位置
这件事的复杂度,已经接近一个研究团队要做的工作量。从硬件采购、网络拓扑搭建、自定义数值格式设计、DPDK kernel-bypass 通信、same-ELF SMP 多核并行扩展、异构流水线编排——到最终 104857601是质数吗 的 16.171 tok/s。
但正因为没有商业约束,很多怪路线才有机会出现。fp9 不会出现在任何大厂的 format 标准里——AVX-512 提供了 _mm512_dpbf16ps 这样的 bf16 乘加指令(Intel Intrinsics Guide),AVX2 时代只能用 fp32 FMA,只要有任何 fp8 的原生支持,都不会有人搞出这种奇怪的东西。用 32 台 N100 跑 DeepSeek-V3.2(685B 参数)的 MoE——有人用树莓派跑过 Ernie 0.3B 和 Phi-3 之类的小模型,但更多厂商的做法是去采购服务器,而不是用一堆很菜的 desktop 级小机器拼成一个系统。
这些“怪”之所以成立,恰恰是因为它们不需要通过任何人的 ROI 审批。
我不想把它写成创业神话。它就是一个从评测鸭开始、一路被硬件约束和好奇心推着走的个人项目。这件事的意义不在于最终的那个数字,而在于——它证明了一个人用一批“不够格”的小机器,绕开所有主流技术栈,也能把一件事推到“居然能用”的位置。
继续阅读
最后修改:2026-04-12。
项目声明 / Project Disclaimer
本项目为作者以个人身份、利用业余时间推进的个人娱乐项目;除非另有明确说明,它与作者的任何雇主、客户、学校、单位或其他组织均无合作、雇佣、委托、赞助或背书关系,也不代表任何该等主体的立场。除普通个人捐赠外,本项目未获得任何资金支持。
This project is a personal hobby project developed by the author in a personal capacity and in personal time. Unless explicitly stated otherwise, it has no collaboration, employment, commission, sponsorship, endorsement, or institutional affiliation with any employer, client, school, partner organization, or other entity, and it does not represent any such party's views. No funding was received for this project except ordinary personal donations.
许可 / License
除非另有说明,本页原创文字、本站原创图片与本站原创图表采用 CC BY-NC-ND 4.0 发布。
转载时请保留原文标题、署名“JudgeDuck AI”、发布日期与原始链接;禁止商业转载、改写、摘编、翻译或基于原文创作演绎作品。
第三方商标、外部链接内容,以及文中另有标注的材料,不在上述许可范围内。
Unless otherwise noted, the original text, original images, and original figures on this page are licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.