第 5 章 DPDK 与“一鸭三吃”
通信栈不是一开始就设计成 DPDK 的。它是被一组可量化的数据逼出来的。
5.1 起点:socket 没有复用
项目进入 2025 年秋季的时候,duck 侧的 forward 已经能跑,但性能还很脆弱。
最早暴露的问题是 socket 复用。每次向 duck 发送数据时,如果代码逻辑是“为每个请求新建一个 UDP socket,用完关掉”,在高频调用场景下会很快耗尽端口资源。症状是请求开始失败,或者端口绑定报错。
修复思路直接:把每个 duck IP 对应的 UdpSocket 缓存到一个全局 map 里,复用而不是每次重建。修完之后系统至少能稳定运行了——不再因为 socket 耗尽而崩,但这只是“能跑”,还不是“能用”。
5.2 看见第一个真正的瓶颈
2025 年 10 月 1 日前后,第一次认真量了 forward 的端到端时间。
当时用的是多线程模式:每只 duck 对应一个线程,线程负责发包给那只鸭、等待响应、回来。观察到的现象是:
- 14 只鸭子的第一次发送完成时间,能差到 0.35 ms
- 仅仅是“Forwarding to duck ...”这些日志打出来的时间,自己就能拉开 0.2 ~ 0.3 ms
对于一个目标在 2.5 ms 左右的 MLP forward,光是“开始发包”这个操作就能让鸭子们差出 10% ~ 15%,这不是小问题。
诊断很清楚:每个线程在自己的 busy loop 里等,而 Linux 内核时间片的分配让这些线程不会精确地同时调度上 CPU。结果是“每鸭一个线程忙等”的设计,实际上在等 Linux 的调度器帮忙排队,而不是真正地并发发包。
这是后来切换到 async Rust 的真实动机:不是语言风格偏好,而是想把“每鸭一个忙等线程”改成事件驱动的异步调度,用更少的 CPU 资源管理更多的并发连接。
5.3 async Rust + sendmmsg/recvmmsg
Tokio 阶段
2025 年 10 月前后,通信层切换到了 Tokio async 路径。到 2025-10-07 这一批实验时,这条路已经在 tp31 和 tp32 规模上真跑过。
但 async Rust 解决的是“调度开销”问题,不能解决另一个问题:即使用了 async,每收一个 UDP 包仍然是一次 recvmsg syscall,32 只鸭子的响应包就是 32 次 syscall。syscall 本身有 overhead,而且会触发用户态/内核态的上下文切换。
recvmmsg/sendmmsg
2025 年 10 月 18 日,recvmmsg 已经跑通 POC:
图:recvmmsg POC 跑通时的截图,2025-10-18。
Linux recvmmsg(2) 允许单次 syscall 收多个消息,sendmmsg(2) 同理可以单次 syscall 发多个包。这两个接口是在“单包单 syscall”路径上能做的最后一步优化——把“32 次 syscall 收 32 个响应”变成“1 次 syscall 收最多 32 个响应”。
到 d8a1248 non-dpdk baseline(2025-11-30)这个提交,Rust 主线里已经有完整的 async broadcast + sendmmsg / recvmmsg_batch 实现(对应文件 src/duck/duck_run_async.rs、src/duck/duck_run_async_broadcast.rs、src/duck/utils.rs)。也就是说,在转向 DPDK 之前,已经做过了一轮很认真的批量 syscall 优化。
5.4 用数字把 syscall 墙钉实
2025 年 10 月 19 日,做了一批系统性的 breakdown 测试,覆盖不同模型、不同 tp 规模(tp1/2/4/8/16/31),以及 sendrecvmmsg 和 fastprepare 两个版本族。
从这批日志里能直接读出几组关键数字:

图:0.6B tp24 的 forward 日志,duck forward 本体约 109 ~ 112 µs,但 Rust 端到端仍达 546 µs,2025-10-19。

图:大 payload 档位的 forward 日志,send/recv 各占约 0.47 ~ 0.49 ms,2025-10-19。
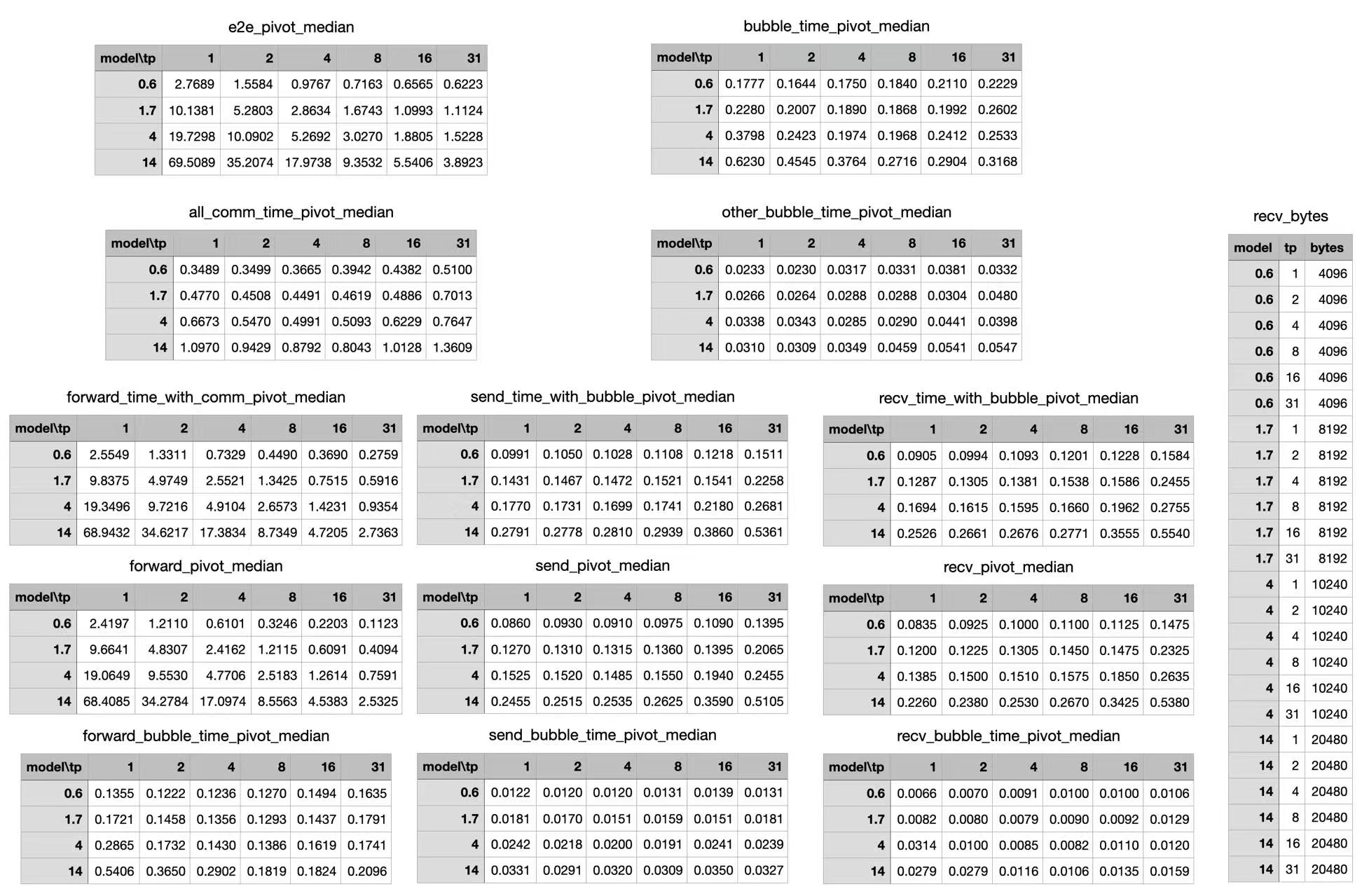
图:forward 各阶段 breakdown 汇总表,可以看到 send/recv 的固定项和带宽项,以及 tp8 以上额外成本的抬升,2025-10-19。
核心数字:
| 场景 | duck forward 本体 | Rust 端到端 |
|---|---|---|
| 0.6B tp24 | 约 109 ~ 112 µs | 约 546 µs |
| 大 payload 档位 | 约 3.02 ms | 约 4.277 ms |
大 payload 下,send 和 recv 各自都有约 0.47 ~ 0.49 ms 的额外成本。这两项加在一起,就是端到端和 duck 侧本体之间的差距的主体来源。
还有另一个指标更直接地说明了问题所在:duck 侧第一个 ACK 到最后一个 ACK 的时间跨度约 160 µs,但 host 侧的 recv 时间窗口却被拉到 200 µs 以上。
duck 端已经“同时”算完并回包了,host 端却还没全部收到——这就是所谓的“duck stampede”(鸭群踩踏):duck 们几乎同时发回 UDP 包,但 host 的 Linux 内核网络栈在处理这批同时到达的包时引入了不可预测的调度延迟,导致明明只需要 160 µs 就能收完的包,在 host 侧被拉成了 200 µs 以上。
这时候问题的性质已经很清楚了:不是 duck 算得慢,也不是批量 syscall 不够聪明,而是 host 的内核网络栈本身就不适合处理这种“32 只 duck 几乎同时回包”的模式。
5.5 认真学 DPDK,重新设计架构
到 2025 年 11 月 23 日,这条线已经收束到一个很明确的判断:这一步不是“想当然开始写 DPDK”,而是在已经把 userspace 路径压到足够清楚之后,必须认真研究 C++ DPDK 的程序设计架构,并明确要做 Python master → Rust controller → per-NIC C++ DPDK worker 这套三层结构。
DPDK(Data Plane Development Kit)的核心机制是让用户态程序直接轮询 NIC 的 RX/TX descriptor ring,完全绕过 Linux 内核的中断处理和调度器。网卡收到包不是中断 CPU,而是 CPU 主动去 NIC 的 descriptor ring 里取。这使得每个包的处理延迟几乎完全由软件决定,不再受内核调度器的随机性影响。
架构决策也在这时候定下来了:
- 每张 NIC 对应一个专属 C++ worker 线程,绑定到一个独立的 lcore
- master 线程(Rust 侧)只发控制命令,不直接做包收发
- 热路径里不让 Python 介入
- 队列 ownership 和 lcore 绑定是架构原则,worker 之间不共享 NIC queue
这和 DPDK 官方文档对 PMD(Poll Mode Driver)架构的建议高度一致:receive 和 transmit queue 不应被多个 lcore 共享,否则会引入锁争用;热路径上尽量避免 interrupt overhead,用 ring 做异步通信。
语言选择:在这个阶段,甚至认真考虑过“能不能用 Rust 的 DPDK 绑定来做”。当时社区里确实存在一些 Rust DPDK 的尝试,但评估后的结论很明确:DPDK 的官方、稳定、被大规模验证的路径在 C++(libdpdk),而 Rust 绑定在 API 覆盖度、版本同步和调试工具链上还不够成熟。对于热路径上不允许出错的系统来说,C++ 是更正规的选择。这也是最终定下“Rust 做编排、C++ 做 DPDK 热路径”这条分工线的直接原因——不是因为 Rust 不能做网络,而是因为 DPDK 本身的生态重心在 C++。
5.6 仓库里的转折点
在代码层面,DPDK 的转折有两个清晰的时间戳:
d8a1248 non-dpdk baseline(2025-11-30)
这个提交虽然已经带了部分 cpp/dpdk_* 相关文件,但 active 主线仍然是 non-DPDK:
src/lib.rs里仍在初始化全局 Tokio multi-thread runtimesrc/duck/duck_run_async_broadcast.rs仍然是 userspace UDP broadcast + sendmmsg/recvmmsg 主线- 提交标题本身就写的是
non-dpdk baseline,是在给 DPDK 切换做切换前的基准记录
6fb5308 dpdk initialization and fast ipc(2025-12-05)
到这个提交,结构才发生真正转折:
src/lib.rs开始启用mod cpp_wrapper和mod dpdk_workers- Python 侧
init()直接调用dpdk_workers::init_nics()和dpdk_workers::init_workers() - Rust 侧开始维护 per-port worker thread、command/response channel、master thread affinity
- C++ 侧新增了明确的接口边界(
cpp/interface.h、cpp/worker.h)
这时才能稳地说:DPDK 不再只是试验代码,它开始成为系统的实际收发骨架。
以下是 2026-03-09 真实系统日志里看到的 DPDK 启动序列:
[2026-03-09 01:06:48.038508 INFO dpdk_workers] DPDK initialized successfully. Found 4 ports.
[2026-03-09 01:06:48.038537 INFO dpdk_workers] Starting worker #0:
(bcast_ip: 10.21.1.255, port_id: 0, lcore_id: 2, host_ip: 10.21.1.1)
[2026-03-09 01:06:48.038577 INFO dpdk_workers] Initializing worker port 0 on lcore 2...
[2026-03-09 01:06:48.040622 INFO dpdk_workers] Starting worker #1:
(bcast_ip: 10.21.2.255, port_id: 1, lcore_id: 4, host_ip: 10.21.2.1)
...4 个 worker 分别绑定在 lcore 2、4、6、8,对应 4 张 Intel E810-C 网卡。到这一步,per-NIC worker + lcore 绑定已经不只是设计图,而是实际在役的系统结构。
5.7 最终架构:一鸭三吃
最终落定的系统形态,从 host 侧看是三层:
Python 层(模型主线):负责模型计算逻辑(Attention、lm_head、dense 层)和调度决策。Python 通过 PyO3 接口调用 Rust 层。Python 不直接接触网络包。
Rust 层(编排层):负责 duck 的状态管理(IP、所在广播域、权重是否已载入、会话状态)、forward 的各阶段编排(prepare → send → judge_wait → fetch → reduce),以及 buffer 管理和 timing 统计。Rust 通过 FFI 调用 C++ DPDK 层。
C++ DPDK 层(热路径):每张 NIC 一个 worker 线程,绑定独立 lcore,轮询 RX/TX descriptor ring,以 rte_eth_rx_burst / rte_eth_tx_burst 收发 UDP 包,完全在 userspace 里运行,不经过 kernel 调度。
“一鸭三吃”是对这套架构形态的概括:同一只 duck 节点,在这套系统里被三层同时使用——Python 层发起计算请求,Rust 层管理它的状态,C++ DPDK 层处理它的网络流量。这三层各司其职,没有哪层需要跨自己的边界去管另一层的职责。
这套三层结构的另一个重要好处是:每一层都可以独立优化,而不影响其他层。C++ DPDK 的热路径保持最简;Rust 的业务逻辑保持可读;Python 的模型计算保持可移植。这是最终系统结构稳定下来的原因,而不是某个事先规划的设计目标。
5.8 从 non-DPDK 到 DPDK 的代价
切换到 DPDK 不是没有代价的。
DPDK 的 worker 线程在 lcore 上轮询时会持续占满一个 CPU 核,哪怕当前没有包要处理。4 个 worker = 4 个核长期 busy。对于 i9-13900K 这台 24 核机器来说,这个比例是可以接受的;但从软件侧来看,这意味着系统必须把 CPU 资源按功能做精细的 partition,master 线程绑定到 worker 核之外的核集合(set_thread_affinity 排除 worker lcore),避免竞争。
DPDK 的初始化也更复杂:需要 hugepage 配置、VFIO 驱动绑定、IOMMU 设置、EAL 初始化等步骤,这些都是普通 socket 程序不需要操心的内容。
这些成本是在已经确认了“内核网络栈就是瓶颈、sendmmsg/recvmmsg 已经做到头”之后,才值得去付的代价。DPDK 不是第一步,而是把所有能在 userspace 里做的优化做完之后,剩下的那一步。
5.9 系统形态在这里定下来
回头看,这条演化路线是连贯的:先解决 socket 复用,再把“每鸭一个忙等线程”改成 async 调度,再用 sendmmsg / recvmmsg 减少 syscall,最后通过 breakdown 看清 host 侧的内核网络栈已经成了主要障碍。到了这一步,改用 DPDK 就不再像一次冒险,而更像顺着问题本身走到的结果。
系统的分工也在这里稳定下来:Python 负责模型主线,Rust 负责编排和状态,C++ DPDK worker 负责热路径收发。后面继续加模型、加优化、加更复杂的 runtime,这个基本形状都没有再变。
项目声明 / Project Disclaimer
本项目为作者以个人身份、利用业余时间推进的个人娱乐项目;除非另有明确说明,它与作者的任何雇主、客户、学校、单位或其他组织均无合作、雇佣、委托、赞助或背书关系,也不代表任何该等主体的立场。除普通个人捐赠外,本项目未获得任何资金支持。
This project is a personal hobby project developed by the author in a personal capacity and in personal time. Unless explicitly stated otherwise, it has no collaboration, employment, commission, sponsorship, endorsement, or institutional affiliation with any employer, client, school, partner organization, or other entity, and it does not represent any such party's views. No funding was received for this project except ordinary personal donations.
许可 / License
除非另有说明,本页原创文字、本站原创图片与本站原创图表采用 CC BY-NC-ND 4.0 发布。
转载时请保留原文标题、署名“JudgeDuck AI”、发布日期与原始链接;禁止商业转载、改写、摘编、翻译或基于原文创作演绎作品。
第三方商标、外部链接内容,以及文中另有标注的材料,不在上述许可范围内。
Unless otherwise noted, the original text, original images, and original figures on this page are licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.